数据库概念
数据库,简而言之可视为电子化的文件柜——存储电子文件的处所,用户可以对文件中的数据运行新增、截取、更新、删除等操作。
所谓“数据库”系以一定方式储存在一起、能予多个用户共享、具有尽可能小的冗余度、与应用程序彼此独立的数据集合
数据库管理系统,是为管理数据库而设计的电脑软件系统,一般具有存储、截图、安全保障、备份等基础功能
现在我们通常使用关系型数据库管理系统来存储和管理数据,所谓的关系型数据库,是建立在关系模型基础上的数据库,借助于集合代数等数学概念和方法来处理数据库中的数据。
展示出来的界面:
实际存储数据内容:

- 表头: 每一列的名称
- 列: 具有相同数据类型的数据的集合
- 行:每一行用来描述某条记录的具体信息
- 值:行的具体信息,每个值必须与该列的数据类型相同
- 键:特殊的列,这一列的值在当前列中具有唯一性
关系型数据库的特点
- 数据库以表格的形式出现
- 每行为各种记录名称
- 每列位记录名称所对应的数据域
- 许多的行和列组成一张表单
- 若干的表单组成 database 数据库
MySQL数据库
MySQL 是一个关系型数据库管理系统,由瑞典 MySQL AB 公司开发,目前属于 Oracle 公司。MySQL 是一种关联数据库管理系统,关联数据库将数据保存在不同的表中,而不是将所有数据放在一个大仓库内,这样就增加了速度并提高了灵活性。
- MySQL 是开源的,所以你不需要支付额外的费用。
- MySQL 支持大型的数据库。可以处理拥有上千万条记录的大型数据库。
- MySQL 使用标准的 SQL 数据语言形式。
- MySQL 可以运行于多个系统上,并且支持多种语言。这些编程语言包括 C、C++、Python、Java、Perl、PHP、Eiffel、Ruby 和 Tcl 等。
- MySQL 对PHP有很好的支持,PHP 是目前最流行的 Web 开发语言。
- MySQL 支持大型数据库,支持 5000 万条记录的数据仓库,32 位系统表文件最大可支持 4GB,64 位系统支持最大的表文件为8TB。
- MySQL 是可以定制的,采用了 GPL 协议,你可以修改源码来开发自己的 MySQL 系统
MySQL的安装
https://dev.mysql.com/downloads/mysql/ 官网提供了所有平台的MySQL版本下载,下载对应版本的MySQL,下载完成后根据引导安装即可。
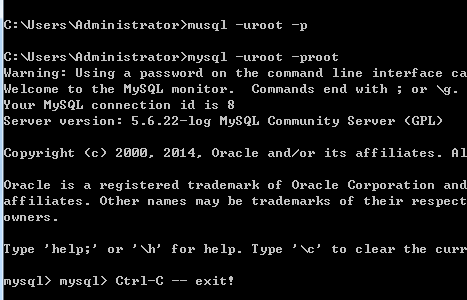
在windows下跟随引导安装mysql完成后,安装过程中会提示设置账号和密码,这里直接将账号和密码设置为root /root ,完成安装,想要在cmd中进入msyql的命令行,必须将mysql添加到系统环境变量Path路径中。
C:\Program Files\MySQL\MySQL Server 5.6\bin
在命令行中执行mysql -uroot -proot,进入到mysql的命令行
Navicat 数据库管理工具
下载并安装navicat进行数据库管理
创建、删除数据库
create database 数据库名;
drop database 数据库名;
选择数据库
use 数据库名
接下来你的所有操作都会在这个数据库中执行
MySQL数据类型
在mysql中支持多种类型的数据结构,大致可以分为三类: 数值、时间和字符串。
- 数值类型
| 类型 | 大小 | 范围(有符号) | 范围(无符号) | 用途 |
|---|---|---|---|---|
| TINYINT | 1 字节 | (-128,127) | (0,255) | 小整数值 |
| SMALLINT | 2 字节 | (-32 768,32 767) | (0,65 535) | 大整数值 |
| MEDIUMINT | 3 字节 | (-8 388 608,8 388 607) | (0,16 777 215) | 大整数值 |
| INT或INTEGER | 4 字节 | (-2 147 483 648,2 147 483 647) | (0,4 294 967 295) | 大整数值 |
| BIGINT | 8 字节 | (-9,223,372,036,854,775,808,9 223 372 036 854 775 807) | (0,18 446 744 073 709 551 615) | 极大整数值 |
| FLOAT | 4 字节 | (-3.402 823 466 E+38,-1.175 494 351 E-38),0,(1.175 494 351 E-38,3.402 823 466 351 E+38) | 0,(1.175 494 351 E-38,3.402 823 466 E+38) | 单精度 浮点数值 |
| DOUBLE | 8 字节 | (-1.797 693 134 862 315 7 E+308,-2.225 073 858 507 201 4 E-308),0,(2.225 073 858 507 201 4 E-308,1.797 693 134 862 315 7 E+308) | 0,(2.225 073 858 507 201 4 E-308,1.797 693 134 862 315 7 E+308) | 双精度 浮点数值 |
| DECIMAL | 对DECIMAL(M,D) ,如果M>D,为M+2否则为D+2 | 依赖于M和D的值 | 依赖于M和D的值 | 小数值 |
- 时间类型
| 类型 | 大小 (字节) | 范围 | 格式 | 用途 |
|---|---|---|---|---|
| DATE | 3 | 1000-01-01/9999-12-31 | YYYY-MM-DD | 日期值 |
| TIME | 3 | '-838:59:59'/'838:59:59' | HH:MM:SS | 时间值或持续时间 |
| YEAR | 1 | 1901/2155 | YYYY | 年份值 |
| DATETIME | 8 | 1000-01-01 00:00:00/9999-12-31 23:59:59 | YYYY-MM-DD HH:MM:SS | 混合日期和时间值 |
| TIMESTAMP | 4 | 1970-01-01 00:00:00/2038结束时间是第 2147483647 秒,北京时间 2038-1-19 11:14:07,格林尼治时间 2038年1月19日 凌晨 03:14:07 | YYYYMMDD HHMMSS | 混合日期和时间值,时间戳 |
- 字符串类型
| 类型 | 大小 | 用途 |
|---|---|---|
| CHAR | 0-255字节 | 定长字符串 |
| VARCHAR | 0-65535 字节 | 变长字符串 |
| TINYBLOB | 0-255字节 | 不超过 255 个字符的二进制字符串 |
| TINYTEXT | 0-255字节 | 短文本字符串 |
| BLOB | 0-65 535字节 | 二进制形式的长文本数据 |
| TEXT | 0-65 535字节 | 长文本数据 |
| MEDIUMBLOB | 0-16 777 215字节 | 二进制形式的中等长度文本数据 |
| MEDIUMTEXT | 0-16 777 215字节 | 中等长度文本数据 |
| LONGBLOB | 0-4 294 967 295字节 | 二进制形式的极大文本数据 |
| LONGTEXT | 0-4 294 967 295字节 | 极大文本数据 |
CHAR 和 VARCHAR 的区别:
定义一个char[10]和varchar[10],如果存进去的是‘abcd’,那么char所占的长度依然为10,除了字符‘abcd’外,后面跟六个空格,而varchar就立马把长度变为4了,取数据的时候,char类型的要用trim()去掉多余的空格,而varchar是不需要的。
MySQL创建数据表
create table 表名 (字段名称,字段类型(长度));
#int后面不写长度,会给默认长度11
#一般来说 我们会把主键设置为 自动递增,每次增加一行数据,主键+1
create table school(
school_id int auto_increment,
school_code int(5),
school_name varchar(100),
school_addr varchar(100),
insert_time datetime,
primary key(school_id)
);
删除数据表
drop table 表名
drop table school;
插入数据
insert into table_name (field1,field2,....) values (value1,value2,....);
insert into table_name values (value1,value2,....);
#类似python中的位置参数和 关键字参数
insert into school(school_code,school_name,school_addr,insert_time)
values
(11111,"北京大学","中国北京",now());
insert into school(school_code,school_name,school_addr,insert_time)
values
(22222,"清华大学","中国北京",now());
insert into school(school_code,school_name,school_addr,insert_time)
values
(33333,"北京科技大学","中国北京",now());
insert into school
values
(4,44444,"哈佛大学","美国",now());
insert into school
values
(0,55555,"哈尔滨佛学院","哈尔滨",now());
查询数据
select 数据名称1,数据名称2
from 表名
where 条件
limit 查询条数
offset 查询偏移
# 查询全部
select * from school;
# 查询全部的学校编号和名字
select school_code,school_name from school;
# 查询来自中国北京的学校编码和名字
select school_code,school_name from school where school_addr = "中国北京";
# 查询来自中国北京的学校编码和名字,只显示2条
select school_code,school_name from school where school_addr = "中国北京" limit 2;
# 查询来自中国北京的学校编码和名称,从第二条开始查询,只显示1条
select school_code,school_name from school where school_addr = "中国北京" limit 2 offset 2;
Where 语句
where 语句类似python语言中的if条件,检索出满足条件的数据,同时可以使用and or逻辑语句来查询
select school_code,school_name from school where school_addr = "中国北京" and school_name = "北京大学";
select school_code,school_name from school where school_addr = "中国北京" or school_addr = "美国";
在where语句中还可以使用操作符来进行匹配
| 操作符 | 描述 | 实例 |
|---|---|---|
| = | 等号,检测两个值是否相等,如果相等返回true | (A = B) 返回false。 |
| <>, != | 不等于,检测两个值是否相等,如果不相等返回true | (A != B) 返回 true。 |
| > | 大于号,检测左边的值是否大于右边的值, 如果左边的值大于右边的值返回true | (A > B) 返回false。 |
| < | 小于号,检测左边的值是否小于右边的值, 如果左边的值小于右边的值返回true | (A < B) 返回 true。 |
| >= | 大于等于号,检测左边的值是否大于或等于右边的值, 如果左边的值大于或等于右边的值返回true | (A >= B) 返回false。 |
| <= | 小于等于号,检测左边的值是否小于于或等于右边的值, 如果左边的值小于或等于右边的值返回true | (A <= B) 返回 true |
select school_code,school_name from school where school_id >= 3;
like语句
# where 条件中还可以用like语句来进行模糊匹配
# 查询出名字包含北京的大学信息
# like通常和%一起使用,但是如果不使用%那么他的效果就和 =号一样
select school_code,school_name from school where school_name like "北京%";
更新数据
#将查询出来的结果中的字段进行更新,可以同时更新多个字段
update table_name set field1=new-value1,field2=new-value2
where 条件
update school set school_code=12345,school_addr='中国首都北京' where school_name = "北京大学";
删除数据
#将查询出来的结果全部删除
delete from 表名 where 条件
delete from school where school_addr = "美国";
排序
# 将查询出来的结果排序
select 字段1,字段2 from 表1,表2
order by 字段1,字段2
select * from school order by school_code;
select * from school order by school_code desc;
select * from school order by school_code,school_name;
select * from school order by school_code,school_name desc;
分组
select 字段 from 表
where 条件
group by 字段;
select * from school
group by school_addr;
#计算出现的次数
select *,count(*) from school
group by school_addr;
UNION 操作符
union操作符用于连接两个以上的select语句的结果组合到一个结果集合中
select 字段名称1,字段名称2 from 表名
where 查询条件
union [all]
select 字段名称1,字段名称2 from 表名
where 查询条件
create table school(
id int auto_increment,
school_code int(5),
school_name varchar(100),
school_addr varchar(100),
primary key(id)
);
insert into school(school_code,school_name,school_addr)
values
(11111,"北京大学","中国北京"),
(22222,"清华大学","中国北京"),
(33333,"北京科技大学","中国北京"),
(44444,"哈佛大学","美国"),
(55555,"哈尔滨佛学院","中国哈尔滨");
create table student(
id int auto_increment,
student_name varchar(100),
school_name varchar(100),
primary key(id)
);
insert into student(student_name,school_name)
values
("张一","福州大学"),
("李二","山东大学"),
("苏四","北京大学"),
("钱五","清华大学");
# union合并两个结果集,删除重复的数据
select school_name from school
union
select school_name from student;
select school_name,school_addr from school
union
select student_name,school_name from student;
#union合并两个结果集,不删除重复的数据
select school_name from school
union all
select school_name from student;
聚合函数
用于对一组值进行统计,并且返回唯一值,这些函数被称为聚合函数
count() 统计记录的条数
sum() 求和函数,求出表中某个字段所有值的总和
avg() 求出某个字段,所有值的平均数
max() 求出某个字段的最大值
min() 求出某个字段的最小值
create table student(
id int auto_increment,
student_id varchar(100),
student_name varchar(100),.
student_grade int,
primary key(id)
);
insert into student(student_id,student_name,student_grade)
values
(10101,"小明",65),
(10101,"小华",28),
(10101,"小李",98),
(10101,"小花",25),
(10101,"小琴",98),
(10101,"小马",100),
(10101,"小宋",65);
select count(student_grade) from student;
select sum(student_grade) from student;
select avg(student_grade) from student;
select max(student_grade) from student;
select min(student_grade) from student;
连接查询
SQL中的常用连接查询,交叉连接、内连接、外连接
交叉连接:从一张表表中循环取出每一条记录,每条记录都去另外一张表进行匹配,最终形成的结果叫做笛卡尔积se
select 字段1,字段2 from 表1 cross join 表2
select 字段1,字段2 from 表1,表2,
create table uniforms(
id int auto_increment,
model varchar(100),
primary key(id)
);
insert into uniforms(model)
values
('a'),
('b'),
('c');
create table student(
id int auto_increment,
student_name varchar(100),
school_name varchar(100),
primary key(id)
);
insert into student(student_name,school_name)
values
("张一","福州大学"),
("李二","山东大学"),
("苏四","北京大学"),
("钱五","清华大学");
select * from student,uniforms;
select * from student cross join uniforms;
select mode from student cross join uniforms;
内连接: 组合两个表的记录,返回关联字段相符的记录,也就是返回两个表的交集部分

create table student(
id int auto_increment,
student_name varchar(100),
school_name varchar(100),
primary key(id)
);
insert into student(student_name,school_name)
values
("张一","福州大学"),
("李二","山东大学"),
("苏四","北京大学"),
("钱五","清华大学");
create table student_grade(
id int auto_increment,
student_name varchar(100),.
grade int,
primary key(id)
);
insert into student_grade(student_name,grade)
values
("张一",65),
("李二",28),
("孟五",65),
("钱六",28);
select * from student join student_grade on student.student_name = student_grade.student_name;
select student.student_name,student.school_name,student_grade.grade from student join student_grade on student.student_name = student_grade.student_name;
外连接:
分为 左连接 、右连接
有null
select * from student left join student_grade on student.student_name = student_grade.student_name;
select * from student_grade left join student on student.student_name = student_grade.student_name;
有null
select * from student_grade right join student on student.student_name = student_grade.student_name;
select * from student right join student_grade on student.student_name = student_grade.student_name;
9856
一对一关系
两个表,第一个表中的某一行与第二个表中的一行相关,同时第二个表中的某一行吗,也只与第一个表中的一行相关,这两个表为1对1关系。
- 一个表包含了太多的数据列,于是分离成两个表
- 为了划分不同的安全级别
- 常用的数据组成一个表
| 学校表 | 学校资产表 | ||||||
|---|---|---|---|---|---|---|---|
| id | 学校编码 | 学校名称 | 学校地址 | id | 学校表id(外键) | 学校资产 | |
| 1 | 11111 | 北京大学 | 中国北京 | 1 | 1 | 500 | |
| 2 | 22222 | 清华大学 | 中国北京 | 2 | 2 | 400 | |
| 3 | 33333 | 北京科技大学 | 中国北京 | 3 | 3 | 300 | |
| 4 | 44444 | 哈佛大学 | 美国 | 4 | 4 | 500 | |
| 5 | 55555 | 哈尔滨佛学院 | 中国哈尔滨 | 5 | 5 | 5 |
create table school(
id int auto_increment,
school_code int(5),
school_name varchar(100),
school_addr varchar(100),
primary key(id)
);
insert into school(school_code,school_name,school_addr)
values
(11111,"北京大学","中国北京"),
(22222,"清华大学","中国北京"),
(33333,"北京科技大学","中国北京"),
(44444,"哈佛大学","美国"),
(55555,"哈尔滨佛学院","中国哈尔滨");
# unique表示唯一性
create table assets(
id int auto_increment,
assets_num int,
school_id int unique,
primary key(id),
constraint fk_school foreign key(school_id) references school(id)
);
insert into assets(assets_num,school_id)
values
(500,1),
(400,2),
(300,3),
(500,4),
(5,5);
select * from school a left join assets b on a.id = b.school_id;
一对多关系
第一张表的一行可以与第二张表的多行相对应
一对多关系是最常见的关系类型
| 学校表 | |||
|---|---|---|---|
| id | 学校编码 | 学校名称 | 学校地址 |
| 1 | 11111 | 北京大学 | 中国北京 |
| 2 | 22222 | 清华大学 | 中国北京 |
| 3 | 33333 | 北京科技大学 | 中国北京 |
| 4 | 44444 | 哈佛大学 | 美国 |
| 5 | 55555 | 哈尔滨佛学院 | 中国哈尔滨 |
| 老师表 | |||
| id | 老师编码 | 老师名字 | 老师所属学校id |
| 1 | 101 | 李白 | 1 |
| 2 | 102 | 杜甫 | 1 |
| 3 | 103 | 白居易 | 1 |
| 4 | 201 | 孟浩然 | 2 |
| 5 | 202 | 李贺 | 2 |
| 6 | 301 | 苏轼 | 3 |
create table teacher(
id int auto_increment,
teacher_code int,
teacher_name varchar(100),
school_id int,
primary key(id),
constraint fk_teacher foreign key(school_id) references school(id)
);
insert into teacher(teacher_code,teacher_name,school_id)
values
(101,"李白",1),
(102,"杜甫",1),
(103,"白居易",1),
(104,"孟浩然",2),
(202,"李贺",2),
(301,"苏轼",3);
多对多关系
多对多的关系是无法直接在两张表中表示关系的,需要借助第三张表
| 老师表 | 老师-学生表 | ||||||
|---|---|---|---|---|---|---|---|
| id | 老师编码 | 老师名字 | 老师所属学校id | id | 老师id | 学生id | |
| 1 | 101 | 李白 | 1 | 1 | 1 | 1 | |
| 2 | 102 | 杜甫 | 1 | 2 | 1 | 2 | |
| 3 | 103 | 白居易 | 1 | 3 | 1 | 3 | |
| 4 | 201 | 孟浩然 | 2 | 4 | 1 | 4 | |
| 5 | 202 | 李贺 | 2 | 5 | 1 | 5 | |
| 6 | 301 | 苏轼 | 3 | 6 | 1 | 6 | |
| 7 | 2 | 7 | |||||
| 学生表 | 8 | 2 | 1 | ||||
| id | 学生学号 | 学生名字 | 9 | 2 | 2 | ||
| 1 | 10101 | 小明 | 10 | 2 | 3 | ||
| 2 | 10102 | 小华 | 11 | 3 | 4 | ||
| 3 | 10103 | 小李 | 12 | 3 | 5 | ||
| 4 | 10104 | 小花 | 13 | 3 | 6 | ||
| 5 | 10105 | 小琴 | 14 | 3 | 7 | ||
| 6 | 10106 | 小马 | 15 | 3 | 1 | ||
| 7 | 10107 | 小宋 | 16 | 3 | 2 |
create table teacher(
id int auto_increment,
teacher_code int,
teacher_name varchar(100),
primary key(id)
);
insert into teacher(teacher_code,teacher_name)
values
(101,"李白"),
(102,"杜甫"),
(103,"白居易"),
(104,"孟浩然"),
(202,"李贺"),
(301,"苏轼");
create table student(
id int auto_increment,
student_id int,
student_name varchar(100),
primary key(id)
);
insert into student(student_id,student_name)
values
(10101,"小明"),
(10101,"小华"),
(10101,"小李"),
(10101,"小花"),
(10101,"小琴"),
(10101,"小马"),
(10101,"小宋");
create table tearcher2student(
id int auto_increment,
teacher_id int,
student_id int,
constraint fk_student2 foreign key(student_id) references student(id),
constraint fk_tearcher2 foreign key(teacher_id) references teacher(id),
primary key(id)
);
insert into tearcher2student(teacher_id,student_id)
values
(1,1),
(1,2),
(1,3),
(1,4),
(1,5),
(1,6),
(1,7),
(2,1),
(2,2),
(2,3),
(2,4),
(3,5),
(3,6),
(3,7);